Importing Excel Spreadsheet Tables
An Excel file is similar to a set of database tables. The column names each table are stored in the cells of the spreadsheets, above the data that should be imported.
Preparation
Given the flexibility afforded by Excel spreadsheets compared to traditional databases, you must take some precautions to help ensure Excel data is imported reliably and accurately.
Multiple Sheets
The Excel importer is capable of importing from multiple sheets in a single Excel file. By default, all mappings in the import mapping file are applied to all sheets, meaning that every sheet will have its data imported according to the map file.
Sheets will be imported in ascending alphanumeric order by name, not by display order in Excel.
If you require some mappings to only apply to sheets with specific names, enter a Specmatch conforming filter in the SHEET column of the applicable mappings in the mapping file.
Table Structure
The Excel importer will search for the column names in any row between row 1 and row 20. The first row containing data in the highest number of columns will be chosen as the row of column names.
Warning: Column headings are expected to be found in either row 1 or row 2 of the spreadsheet. Due to an Excel driver issue, if column headings are in any other row, the data read from those columns may be interpreted incorrectly.
- The maximum number of columns that can be imported from a spreadsheet table is 200.
- Column headings should be text (not anything Excel would treat as a number, or other datatype).
- Column headings should not contain any merged cells.
- Ensure all columns have a heading name (if there are blanks, it is best to fill them with a dummy heading).
Data Consistency
The more consistent your data is in your Excel table, the easier it will be to create a working map file.
- Ensure that each column is only used for one type of data.
- Do not use merged cells.
- Do not leave the value in a cell blank if you intend for it to be the same as a cell above. Instead, ensure each cell contains the value, even if it means some columns contain a lot of repetition.
- Blank rows in the data are permitted, but if there are more than 5 blank rows together, the Excel importer will consider this to mark the end of the table data.
Procedure
-
Select "Import Data" from the Instrument Manager file menu.
-
Select the tag table into which the components should be imported. In a project database created from the default database template there will be only a single tag table.
-
Select "Excel Table" from the list of "Types of Files to Import".
-
Click the [Next] button.
-
Select the import mapping file to use. This will have to be prepared in advance.
You can drag and drop a map file onto this dialog.
-
Click the [Next] button.
-
Click the [Add File] button. Select the spreadsheet files to import and click the [Open] button. This adds the files to the file list. Any number of files can be added here. Files can be removed from the list by selecting them and clicking the [Remove File] button.
You can also drag and drop Excel files onto this dialog.
-
Click the [Finish] button to perform the importing.
-
If the imported table contains component names that already exist in your project database, then you will be asked if the existing component data should be overwritten. Existing components will not be completely overwritten. Only the data that is mapped from the imported file will be overwritten.
Drag and Drop
You can now drag the files that are to be imported and drop them onto the "Select Files" dialog rather than browsing for those files.
Finding the column names and finding the data
Importing tables stored in spreadsheets differs from importing other table types because Instrument Manager must determine where to find the column names. In other table types the column names are a known part of the file structure.
Instrument Manager will search for the column names in any row between row one and row twenty. The first row containing data in the highest number of columns will be chosen as the row of column names. The maximum number of columns that can be imported from a spreadsheet table is 200.
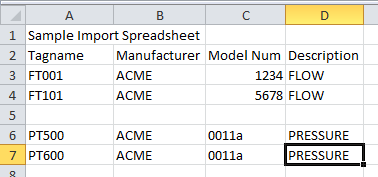
The example spreadsheet shown at the top contains four columns of data. The first row with four cells that are not empty is row 4. Therefore Instrument Manager determines that the column names in the example spreadsheet are stored in row 4.
Data is located in the rows following the row of column names. There can be a maximum of five blank rows between subsequent data rows.
In the example spreadsheet shown at the top there are only two blank rows, rows 5 and 8, and they are separate from each other - neither exceeds five blank rows. Instrument Manager will look for data in all of the rows from row 5 to row 10 inclusive.
Check the import log file
During the import, a log file is created with diagnostic information.
Within the log file you can see the analysis for each sheet in each selected Excel files:
-
The number of the row that Instrument Manager determined was most likely to contain the column names.
-
The number of columns that were found.
-
The names of the columns along with their column letter from the spreadsheet layout.
Assisting Instrument Manager to import a spreadsheet table
Sometimes you will need to edit the spreadsheet table to assist Instrument Manager to find the columns and the data.
-
If you find that nothing was imported, or you have multiple sheets and too much was imported, then you may need to alter the SHEET filter in the import mappings so that it matches the names of appropriate sheets.
-
If you find that some of the columns were missed then there was probably one or more empty cells in the row of column names. Enter some unused data into the empty cells to ensure that the full row of column names can be found.
If some of the column name cells were merged cells, one column name shown above two or more real columns, then you will need to break the merged cell. You will then need to enter your own column name text into the resulting empty cells so that each of the two or more real columns has its own unique column name.
-
If you find that the wrong row was chosen for the column names then you may need to delete prior rows or fix empty cells in the row of column names, as described above.
-
If you find that only part of a column name was found then the column name cell may have contained a line break or carriage return character to split the data over two rows, or it may simply be two rows of text that you read as one value. You can modify the import map file to use the shorter column name if that is still unique, or you can edit the column name in the spreadsheet to remove the line break character.
-
If you find that column names are repeated (e.g. "TERM STRIP" may appear on more than one column) then you will need to edit the column names to ensure that each is unique.
-
If there are two rows of column names and other information above the real data, you may find that the first row of data that is imported is the "other information" that was below the column names. In this case you will need to delete that row so that the real data comes immediately after the column names.