Import Map Files
The import map file defines how data in a file can be imported into the project database. The map file system is very flexible and thus has many configuration options.
Overview
The following types of file are imported using an import map file:
-
Excel Table (*.xls;*.xlsx;*.xlsm;*.xlsb)
-
Access Database Table (*.mdb)
-
DBF Format Database (*.dbf)
-
Elecdes Project (*.prj)
Importing an Elecdes Project is special because it always defaults to using the same import map file: "EDS Project Import Map.dbf". This map file has been supplied pre-configured to import the various DBF files from an Elecdes project. It follows the format described below and can be modified to suit any special requirements.
Catalog Map Files
Import map files are also used for mapping the columns in the EDS catalog files to the columns in the ratings tables in the project database. They are used when you create or re-select a component from the EDS catalog, not for importing data from foreign data sources. These map files have filenames that end with "... catalog map.dbf". Catalog map files use only simple mapping from one column to another, without any filtering.
Import Map File Location
Import map files can be found in the <EDS>\CABSCHED\ImportMapFiles directory.
Building Complex Import Map Files
When you are creating import map files you should plan to test the import on a temporary database that you can discard, then fine-tune the import map files, then repeat the import until the data is imported as intended.
It is easiest to build the import map file by adding a small number of mappings then testing the results before adding further mappings: first the instrument tags, then add the ratings, then add the terminals, then add terminal strips, cables etc, then add connections and so-on. Repeat this until you have one or more import map files with which you can import your entire data set.
Import Map File Fields
The primary contents of the import map file specify that data from the fields named in FIELD will be imported into the fields named in DESTFIELD. The other columns in the import map file provide only filters, conditions or descriptions for that primary mapping.
| DESTFIELD |
The name of the field in the chosen tag table of the project database into which the data will be imported. The destination for the imported data. Can instead contain a filter for the data to import from the field named in FIELD. |
| FIELD |
The name of the field in the table that is being imported. The source of the data. Can instead contain a formula to use or manipulate one or more fields from the imported table. Can instead contain an assignment for the data to place into the field named in DESTFIELD. Can instead specify a value from a table name, file name, sheet name, or absolute cell reference. Can instead specify a "lookup" to get an alternate value to place into the field named in DESTFIELD that is based on the value found in the field named in the lookup. |
| COMP_TYPE |
The type of component to create for each record that is imported. For relational columns, the COMP_TYPE filters the type of the component that can be linked to the main component created from each record that is imported. |
| ITEM_NUM |
A section number used to identify which entries of the import map file apply to which component when multiple components will be created from each record that is imported. |
| ITEM_DESC |
A brief description of the component or link that is created by the section from the import map file. e.g. "JB T-Strip" or "Connection for wire". This field is optional. You can enter any text that you feel is appropriate. |
| TABLE |
A file or table name filter that specifies only tables whose name matches the pattern defined in TABLE will use that entry of the import map file. This field is optional. If it is empty then all imported tables can use the map file entry. |
| SHEET |
A sheet name filter (for sheets in an Excel spreadsheet) that specifies only sheets whose name matches the pattern defined in SHEET will use that entry of the import map file. This field is optional, and only applies when the source is an Excel file. If this field is blank in a map entry, then all sheets in the Excel file will use the entry. Note: To restrict a map entry to a particular Excel filename (as well as, or instead of a sheet name), use a filter in the TABLE field. |
| DESTTABLE |
The name of the table in the project database that is the destination for the imported data. This field is optional. If it is empty then the data will be imported into the table that is chosen at the beginning of the import procedure. DESTTABLE is most likely to be used when one section of the map file must import to a different table than the other sections. e.g. Importing an I/O channel to the "TerminalGroup_Terminal Groups" table. |
| CONDITIONS |
One of a specific list of conditions that must be met for the entry from the import map file to be applied. If there are no conditions required then this field should be left empty. |
| NOTES |
Any notes or description that you wish to enter in the import map file. This field is optional. |
Mapping Types
Column Mapping
In the simplest case the map file merely defines the 'mapping' of data between columns in the import table and columns in the project database tables.
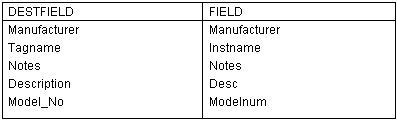
In the example fields in the table to import appear in the "FIELD" column, and fields in the project database appear in the "DESTFIELD" column. Hence data from the "Desc" column in the import table will be extracted into the "Description" column in the project database.
Each row of the map file is a single mapping between the two fields named on that row.
Formula Mapping
Import Map files support the use of Formulae in the FIELD column. Formulae allow data from one or more columns in the import table to be manipulated and combined to produce a final value for the DESTFIELD.
See Formula Evaluator for a description of the syntax required for formulae, and Function Reference for a list of functions that can be used to manipulate data from the import table.
Source Data Parameters
In the context of formula evaluation for import mapping, source data expressions must refer to fields in the table being imported, or a fixed reference.
The field names referenced are not case sensitive.
Concatenating Imported Data
Instead of the name of a single field from the table to import, the "FIELD" column can contain a formula that specifies how to create a composite of fixed text and one or more fields from the table to import. This composite value is inserted into the field of the project database table specified in the "DESTFIELD" column.

In the example, the value from the "Type" field will be followed by a hyphen, then followed by the value from the "Loop" field. If the Type field contains "PIT" and the Loop field contains "120" then the value inserted into the project database would be "PIT-120".
For example, if the "Type" field contains "PIT" and the "Loop" field contains "120" then the value inserted into the "Tagname" column of the tag table in the project database would be "PIT-120".
Assignment Mappings
It is possible to define the data explicitly to be created from the map file. Instead of having a field name in the "FIELD" column, the column can contains the data to insert preceded by the '=' symbol. This is called an assignment mapping.

Data from an assignment mapping will be exactly the same for every component created from that section of the import map file.
An assignment mapping is often used to set the ratings table name, see Ratings Data below.
In the example map file fragment, the assignment mapping will cause the text "FLOW" to be written into the "Function" column of all of the records created using the mappings from the import table.
Fixed References
Sometimes the value you need to use is not in the table itself, but in the metadata of the table, such as the table/sheet name, or the file name. When importing from Excel, you may also have arbitrary data in the first row, before the column headings.
Fixed references allow you to retrieve these values, which are then treated as assignments when entered into FIELD as a column mapping. They can also be used as a field name or source data parameter inside a formula.
| Reference Name | Notes |
|---|---|
| $TABLE | Retrieves the table name (MDB imports), or filename without extension (DBF and Excel imports) of the current import data source. |
| $SHEET | Retrieves the sheet name of the current import data source (Excel only). |
| $A$1 | Extracts the value from cell A1, or any other cell reference (Excel only). |
Lookup Mapping
You may wish to insert into the destination table one of a number of values that are not in the table to import, but that you can choose based on the data in the table to import. For each value found in the table to import, you will "look up" that value in a list to find the corresponding value that you want to insert into your destination table. A lookup provides a mapping from one value to another.
A lookup mapping is the recommended method to set the ratings table name (setting R1_Table), see Ratings Data, below.
Map file:

Lookup table (e.g. TypeCodeToRatingTable.dbf):
A lookup mapping replaces the contents of the "FIELD" column in the map file, must always start with the word "Lookup", and has a strict format of keywords that indicate what each part means. The format of a lookup is as follows:
Lookup <Field name> from <Lookup table DBF name> in <Lookup table column to search> return <Lookup table column to return>
Each part enclosed in <...> is a parameter that may differ between lookup mappings. The words between these parameters ("Lookup", "from", "in" and "return") are the special keywords that must be used.
-
<Field name> is the name of the field from the table to import that contains the value that must be found in the lookup table.
-
<Lookup table DBF name> is the name of a DBF file that is a lookup table, namely a table with two columns of paired values. The two columns are named in the next two parameters.
-
<Lookup table column to search> is the name of the column from the lookup table in which the data from <Field name> must be found.
The "in" keyword and parameter can be omitted if the column is named "CODES".
-
<Lookup table column to return> is the name of the column from the lookup table that contains the corresponding value to return from the found row.
The "return" keyword and parameter can be omitted if the column is named "VALUE".
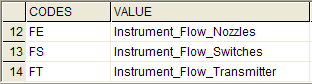
In the example, an instrument will be created and will be named by the contents of the "Tag" field of the table to import. The name of the ratings table for that instrument is set by the lookup mapping in the second row of the map file. The lookup will fetch the data from the "Type" column of the table to import, which would contain an ISA instrument type code (e.g. PIT, FE, etc). The fetched type code is searched for in the "CODES" column of the lookup table file "TypeCodeToRatingTable.dbf". If the type code is found in the "CODES" column then the contents of the "VALUE" column of the lookup table file are put into the "R1_Table" column of the tag table in the project database.
For example, if the "Type" column of the table to import contains the value "FS" then this will be found on row 13 of the lookup table "TypeCodeToRatingTable.dbf", so "Instrument_Flow_Switches" will be set into the "R1_Table" column of the tag record in the project database.
A lookup mapping can also be used as part of formula, by using the MAPLOOKUP formula function. The functionality is the same, however, note the difference in syntax.
Component Types
It is important to define the component type for the component that a section is importing. It is unlikely that the data in an imported table will contain this data, therefore it should be defined in the map file. This is usually done using the "COMP_TYPE" column in the import map file.
It is also possible to set the component type like any other destination column. Put the column name "Component_Type" in the DESTFIELD column of the import map file and an appropriate value either imported, assigned or looked up from the FIELD column.
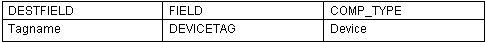
The component type only needs to be specified on one line of each import section. The line that imports the name of the component is usually a good choice.
The component type must be one of the built-in types that is originally part of Cable Scheduler.
The component type text must be exactly correct as it must match the type in the program. This includes spaces between words, e.g. "TERMINAL STRIP". The default supported types are:
AREA, ENCLOSURE, INSTRUMENT, DEVICE, TERMINAL STRIP, TERMINAL, CABLE, CORE, and WIRE.
In the example the component created using the mapping in the import table will be of the type "Device".
Component Type Filter
The "COMP_TYPE" column specifies a filter when specified on the line for a relational column, see Relational Columns below. Used this way the component type specifies the type(s) of component that can be found for the relational column and thus linked to the imported component. For a filter for a relational column you can specify more than one component type in a comma separated list.
Map File Divided into Sections
Rows in the map file can be divided into sections. The configuration information in each of these sections defines the mappings for a single component from each record in the import table. By having more than one section it is possible to import more than one component from each of the records in the import table.
The numbers in the "ITEM_NUM" column define the sections. All mappings with the same item number are considered to be in the same section and apply to importing the same item. Mappings with a different item number are considered to be in a different section and apply to importing a different item. Sections are processed in the order in which they appear in the map file regardless of the actual item number used for each section. This is important for importing containment relationships, see Relational Columns below.

In the example there are two sections, 1 and 2. These will import a device and a terminal using the mappings from the import table.
Multiple Sections versus Multiple Import Map Files
An alternative to separate sections all in one import map file is to use separate import map files and perform an import from the same source tables with each separate import map file. In a simple case both methods will produce the same results. However, the results will be different if conditions are specified for any of the mappings. See Conditions for Mappings below.
Using multiple sections differs from using multiple import map files because Cable Scheduler considers that a component "exists" in the project database only after the import operation is completed, not after one section of the import map file is completed.
-
During one import operation using a single import map file, a component does not "exist" until that entire import is finished, even if that component was created by a previous section of the import map file.
-
During separate imports using separate import map files, a component may already exist from one of the previous import operations.
The order in which source records and sections is processed differs when comparing multiple sections versus multiple map files.
-
When using a map file that contains multiple sections, all map sections are applied to the current source record before moving to the next source record.
-
When using separate map files, all source records are processed using each map file in turn (since each map file is used in a separate import operation that you must run).
If you are importing a complex data set then you can expect to use a combination of separate sections and separate import map files.
Data Filtering for Sections
The sections of the map file can have a data filter associated with them to determine whether or not the section should be used for a particular record in the import table. The data filter can be applied to any field in the import table.

The data filters in the example are those with '==' or '!=' in the "DESTFIELD" column. The part following the '==' (equality) or '!=' (inequality) is a pattern that will be compared to the data in the column in the import table which is specified in the "FIELD" column.
If the data in the column named in "FIELD" does not match the filter then the entire section will be skipped for this record from the imported table.
The supported filters are:
-
'=' or '==' for "equal to"
-
'!=' or '<>' for "not equal to"
-
'<' for "less than"
-
'<=' for "less than or equal to"
-
'>' for "greater than'
-
'>=' for "greater than or equal to"
-
'*' will match any number of letters or digits
-
'?' will match any single letter or digit
-
'@' will match one or more letters
-
'#' will match one or more digits
The pattern can be enclosed in quotation marks, for example: =="FT*".
Multiple filters can be specified in one entry by separating each by a semicolon, for example the filter !="TBC";!="N/A" means that the map file section will only be used for records where the value in the column named in "FIELD" is not "TBC" and is not "N/A".
In the example, the data in the TAG field of the import table, is compared against "FT*". If the tag starts with FT then section 1 will be used, importing an instrument. Otherwise section 2 will be used, importing a device.
Filters can contain multiple patterns, wildcards, and comparisons. See Specmatch for more details about configuring filters.
Relational Columns
In order to import linking information, relational columns can be used to define the parent or container relationships and electrical connection relationships between the imported components. These relational column mappings do not import data. Instead they create links in the database between two components.
Containment (P1) and connection (C1 and C2) are the only type of links that can be imported in this way. (Importing ratings data (R1) is similar but imports data rather than creating links. Ratings data is described below).

Related components are always identified by component name, which is always in the "Tagname" column in the default project database. Therefore the only relationship that you can have in an import map file is "Tagname" with the required combination of "P1:", "C1:" and "C2:" prefixes.
Components that are to be containers must be imported before the components they are to contain. This is accomplished by using a lower section number for the mappings that will import the container components or by importing the container components in a previous import operation.
For each of the three sections in the example map file, a separate component will be imported. The P1:s in the "DESTFIELD" column indicate parent or container items. Two P1:s in a row, "P1:P1:", indicates a grandparent, or two layers of containment. For example, a panel is usually two layers away from a terminal because the panel will contain a terminal strip, device or instrument that then contains the terminal.
A relational column requires that the correct component type is specified, see Component Type Filters above. If a related component could be one of a number of types, then those types should be listed together in a comma separated list, e.g. "DEVICE, TERMINAL STRIP".
In the example, each component is contained by the component imported immediately prior to it. The terminal (item 3) is contained in the instrument (item 2), which is in turn contained in the enclosure (item 1).
See also: Relational Columns.
Relational Filtering
Relational mappings can have extra information specified directly in the map file to ensure the correct components become linked. This is useful when certain data is assumed rather than specified in the imported data. Note that this is not an assignment of a value into a related component. Instead, it is specifying that a related component must have a specific value, most likely a specific Tagname.

In the example, a terminal is contained in a junction box. The terminal is actually in a terminal strip named "TB" that is inside the junction box, but the strip name "TB" is assumed because it's the same terminal strip name in all of the junction boxes. Therefore the second line of the map file specifies that the terminal should be linked to a terminal strip named "TB".
Complete Relational Hierarchy
It is usually important to identify all levels of hierarchy. Consider that you are importing a record that defines a terminal that is part of a terminal strip named non-specifically as "TB" in a junction box named "JB3". It is not enough to specify only the immediate container of the terminal with a relational column "P1:Tagname" with the field containing the text "TB" from the imported data. If there are many terminal strips named "TB" and you specify only this immediate container, then Cable Scheduler would simply find the first terminal strip named "TB" and import your terminal into that strip.
To correctly identify the strip you would also need to specify the panel that contains the strip with a relational column "P1:P1:Tagname" with the field that contains the junction box name "JB3" from the imported data. Cable Scheduler will then look for a terminal strip named "TB" in an enclosure named "JB3" and import the terminal into that strip.
However, if you know that the name of the component is unique then you can use the "AnyParent" condition condition as described below.
Connection Mapping
Connections exist in the conductor records: wires and cable cores / conductors. Each conductor can have two connections, which are linked via the C1 and C2 relational columns, which represent the connection at either end of the single segment of the conductor. You can import connections by specifying a relational column mapping for C1 or C2.

In the example a cable-core/conductor is imported from the field named CORE2. It is contained in the cable that is named in the field CABLE2.
The core/conductor is connected to a terminal that is named in the field TERM1. The connection is created in the project database as a link in the C2 relationship of the core/conductor by specifying "C2:" in DESTFIELD. The container of the terminal is a terminal strip that is named in the field TBLOCK1 and the terminal strip is contained in a junction box that is named in the field JB1.
The relational column mappings that start with "C2:" will ensure that the correct terminal, including its complete relational hierarchy, will be found and connected to the core/conductor.
The core/conductor is also connected to another terminal, this one being named in the field TERM2. The connection is created in the project database as a link in the C1 relationship of the core/conductor by specifying "C1:" in DESTFIELD. The container of the terminal is an instrument that is named in the field TBLOCK2 and the instrument has no named container - so any instrument with the correct name will suffice. It would be expected therefore that the instrument name was unique.
-
C1:Tagname will ensure that a terminal is found with the same name as the text from the field TERM2.
-
C1:P1:Tagname will ensure that the terminal is contained in an instrument with the same name as the text from the field TBLOCK2.
The records for the terminals, instrument, terminal strip and junction box must all be present in the project database to resolve this relationship. They can however have been created by a previous import map section of the same import map file processed during the same import operation which is yet to be completed.
See also: Relational Columns.
Ratings Data
For ratings to be imported for a component, the destination table for the ratings data must be specified. This can be done using an assignment mapping, specifically setting the data for the "R1_TABLE" column. Alternatively you can add the ratings table name directly to the data to be imported. These other two options are described below.
Destination fields that are in the ratings record are specified by the "R1:" prefix in the "DESTFIELD" column of the import map file.
You can assign a fixed value to a field in a ratings record, see Assignment Mappings above.

Cable Scheduler will create a new record in the specified ratings table to contain the ratings for the new component that is imported. The ratings data itself is imported into the ratings record instead of the tag record for all destination fields with an "R1:" prefix.
The example mappings will create an enclosure component and link it to a new rating record in the Enclosure_Enclosures table. The Desc and Width fields in the import table will be read into the Description and Width fields of the new ratings record in the Enclosure_Enclosures table. The Status field of the new ratings record will be assigned the value "Imported".
Another method to set the ratings table is to modify the data files that are to be imported and add a column that specifies the Cable Scheduler ratings table for each component to be created. This is particularly useful for instruments which have numerous different ratings tables (other types, such as enclosures, usually have only the one ratings table so an assignment mapping is sufficient). See also Lookup Mapping above
See also: Relational Columns.
Table Filtering
Each row in the map file can have an associated filter to ensure that it is used for import tables only of a specific name or names. The table filter is stored in the "TABLE" column in the map file. It is specified as a file name pattern to be compared to the import table name (MDB) or filename (DBF, Excel). Table filters are evaluated by Specmatch.

In the example, if the import table starts with "Dev" then the data from the "DEVFUNC" field will be imported into the "Function" field. If the import table starts with "Inst", the data will come from the "DESCFUNC" field.
An alternative to table filtering is to ensure that you choose only the correct tables to be imported with a specific import map file, and use different import map files for different tables to be imported.
The map file for the Elecdes Project import, "EDS Project Import Map.dbf", provides an example of table filtering. The Elecdes Project import will import numerous different DBF format files in one operation using a single import map file. Each imported file requires its own import map file section, so they are filtered by the TABLE column in the import map file.
Excel Sheet Filtering
All sheets in an Excel file will attempt to be imported using the import map file. Therefore, if an Excel file has multiple sheets, and not all are applicable to all sections of the map file, then it is necessary to filter the map file by Excel sheet.
Excel sheets are filtered using a Specmatch filter in the SHEET column of the map file. You should specify an appropriate sheet filter for all entries in the import map file.
SHEET filters can be used in conjunction with TABLE filters (which filter by file name of the chosen Excel files).
Conditions For Mappings
You can specify a number of conditions for mappings in the import map file to either prevent or to force the use of a particular mapping or map file section. Each of the conditions specifies a rule for overwriting data when the project database already contains components that could also be imported; when there are "existing" components.
Components are always identified by component name, which is always in the "Tagname" column in the default project database. A component is considered to exist if there is a record with the same Tagname and the same container hierarchy (as described in Complete Relational Hierarchy above).
Components that are created in the same import operation but from previous sections in the same import map file are not considered to be existing until that import operation is completed. See Multiple Sections versus Multiple Import Map Files above.
NoRatingChange
This condition allows you to specify two ways in which the ratings must not change if the component exists. This condition applies only to a single mapping in the import map file section.
If "NoRatingChange" is specified on the import map file entry that will set the ratings table name, e.g. an assignment mapping for "R1_TABLE", then that single mapping will not be used if the component exists and already has a ratings record. Other import map file entries for importing ratings data may still be used. Use this condition if you know that some of your components have already had a ratings record created and that this import mapping is only for components that do not yet have a ratings record.
If "NoRatingChange" is specified on an import map file entry that will import a field of ratings data, e.g. "R1:Description", then that single mapping will not be used if the component exists and it already has a value in that rating. Use this condition if the ratings of some of your components already contain data that you do not want overwritten but that others are still blank and will be set during this import.
CanExist
This condition tells Cable Scheduler that a component can be imported (an entire section of an import map file may be used) even if the component already exists in the database.
Since this condition applies to an entire section of the import map file, you need specify this condition on only one record of an import section. The line that imports the name of the component is usually a good choice.
Use this condition to suppress the question about overwriting existing components.
MustExist
This condition allows you to specify that an entire section of an import map file may only be used if the component already exists in the database.
Since this condition applies to an entire section of the import map file, you need specify this condition on only one record of an import section. The line that imports the name of the component is usually a good choice.
Use this condition when you want to add data to only existing components. You can use one "MustExist" section and one "MustBeNew" section in the import map file where each section specifies some different mapping for existing or for new components.
MustBeNew
This condition allows you to specify that an entire section of an import map file may only be used if the component does not currently exist in the database.
Since this condition applies to an entire section of the import map file, you need specify this condition on only one record of an import section. The line that imports the name of the component is usually a good choice.
Use this condition when you want to import only new components and skip all existing components (thus protecting any data you may have modified in the project database since they were imported). You can use one "MustExist" section and one "MustBeNew" section in the import map file where each section specifies some different mapping for existing or for new components.
MustExistForRemainder
This condition is similar to "MustExist" except all remaining sections are also skipped if the component does not exist in the project database.
Use this condition if you only want to import components related to an initial component if that initial component already exists in the database. For example, if "MustExistForRemainder" was specified on an import map file section for a cable, then following import map file sections for the cores or conductors of that cable would be skipped if the cable did not exist.
MustBeNewForRemainder
This condition is similar to "MustBeNew" except all remaining sections are also skipped if the component already exists in the project database.
Use this condition if you only want to import components related to an initial component if that initial component does not yet exist in the database. For example, if "MustBeNewForRemainder" was specified on an import map file section for a device, then following import map file sections for the terminals of that device would be skipped if the device already existed.
AlwaysCreate
This condition specifies that a new component must always be created from the import map file section, even if there is an existing component with the same name (and in the same containing component if appropriate).
Exercise caution with this condition because it will always create new components, so you would only want to run the import operation once on any particular project database. Compare this to the MustBeNew condition, which will simply fail to create any components if the data is imported a second time into the same database.
This condition can be useful for importing wires when you know that there will be existing wires with the same name that cannot otherwise be differentiated. Thus you must force the import to create a new wire because otherwise it would find an existing unrelated wire and import the data into that existing wire.
AnyParent
This condition specifies that the imported component will match any existing component based solely on the name of the component without any regard to the parenting of that existing component - i.e. the existing component can have any parent, or no parent.
This condition should always be specified on a mapping that specifies a name of a component. This condition applies only to the specific mapping on which it appears, not to the entire section of the map file. If this condition is specified on the mapping that will set the tagname of the component, then it means that the main component that is being imported can have any parent. If this condition is specified on the mapping that specifies the name of the parent component (e.g. P1:Tagname) then it means that the parent of the main component can have any parent.
Use this condition if you know that all components of this type have unique tagnames and thus you can dispense with specifying the mappings to identify the parenting of the component. This is possibly the case for instruments in that, no matter what area an instrument exists in, it will always have a unique name.
Do not use this condition if there may be numerous existing components with the same tagname but in different parent or container components. For example you are unlikely to be able to specify this condition for importing terminal strips if they are all generically named "X1" for the first strip in each different junction box.
Map File Editor
Map files are DBF format database tables and can be edited using any DBF format compatible editor. The EDS database editor, Database Editor, can be started from the EDS Icons for this purpose.
-
Select "Edit a mapping file" from the "Tools" menu in Cable Scheduler.
-
A file selection box will be displayed.
-
Select the map file to be edited and click [Open].
-
Database Editor be started and will open the selected database file.
The map file can then be edited with the full functionality of Database Editor.